
Jan's Computer Basics:
Processing: Digital Data
Modern computers are digital, that is, all info is stored as a string of zeros or ones - off or on. All the thinking in the computer is done by manipulating these digits. The concept is simple, but working it all out gets complicated.
| 1 bit = one on or off position | 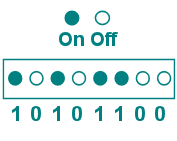 |
| 1 byte = 8 bits |
So 1 byte can be one of 256 possible combinations of 0 and
1.
Numbers written with just 0 and 1, are called binary numbers.
Each 1 is a power of 2 so that the digits in the figure represent the number:
= 2 7 + 0 + 2 5 + 0 + 2 3 + 2 2 + 0 +0
= 128 +0 +32 + 0 + 8 + 4 + 0 + 0
= 172
Every command and every input is converted into digital data, a string of 0's and 1's.
For more information on binary numbers, see Base Arithmetic.
Digital Codes
All letters, numbers, and symbols are assigned code values of 1's and 0's. A number of different digital coding schemes are used by digital devices.
Three common code sets are:
ASCII (used
in UNIX and DOS/Windows-based computers)
EBCDIC (for IBM
System 390 main frames)
Unicode (for Windows NT and recent browsers)
The ASCII code set uses 7 bits per character, allowing 128 different characters. This is enough for the English alphabet in upper case and lower case, the symbols on a regular English typewriter, and some combinations reserved for internal use.
An extended ASCII code set uses 8 bits per character, which adds another 128 possible characters. This larger code set allows for foreign languages symbols like letters with accents and several graphical symbols.
ASCII has been superseded by other coding schemes in modern computing. But it is still used for transferring plain text data between different programs or computers that use different coding schemes.
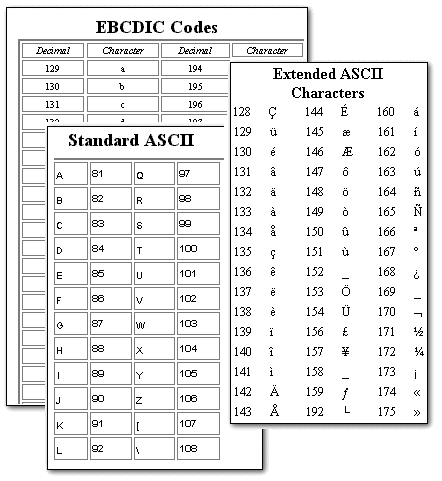
If you're curious to see the table of ASCII and EBCDIC codes, see Character Codes.
Unicode uses 16 bits per character, so it takes twice the storage space that ASCII coding, for example, would take for the same characters. But Unicode can handle many more characters. The goal of Unicode is to represent every element used in every script for writing every language on the planet. Whew! Quite a task!
Version 5 of Unicode has codes for over 107,000 characters instead of the wimpy few hundred for ASCII and EBCDIC. Ninety different scripts can be displayed with Unicode (if your computer has the font needed), including special punctuation and symbols for math and geometry. (Some languages have more than one script like Japanese, which uses three scripts: Kanji, Hiragana, and Katakana.) English and the European languages like Spanish, French, and German use the Latin script. Cyrillic is used several languages including Russian, Bulgarian, and Serbian.
At the Unicode ![]() site you can view sections
of the Unicode code charts
site you can view sections
of the Unicode code charts ![]() . The complete list is
far too
long to put on one page! Click on the name of
a script (red letters on gray) to see a PDF chart of the characters. View
the charts for scripts you never heard of.
. The complete list is
far too
long to put on one page! Click on the name of
a script (red letters on gray) to see a PDF chart of the characters. View
the charts for scripts you never heard of.
Parity
With all these 0's and 1's, it would be easy for the computer to
make a mistake! Parity is a clever way to check for
errors that might occur during processing.
In an even parity system an extra bit (making a total of 9 bits) is assigned to be on or off so as to make the number of on bits even. So in our example above
10101100 there are 4 on bits (the four 1's). So the 9th bit, the parity bit, will
be 0 since we already have an even number of on bits.
In an odd parity system the number of on bits would have to be odd. For our
example number 10101100, there are 4 on bits (the 1's), so the parity bit is set to on, that is 1, to make a total of 5 on bits, an odd number.
If the number of on bits is wrong, an error has occurred. You won't know which
digit or digits are wrong, but the computer will at least know that a mistake occurred.
Memory chips that store your data can be parity chips or non-parity chips. Mixing them together can cause odd failures that are hard to track down.
|
|
| © 1997-2017 Jan Smith All Rights Reserved |
Site Map What's New |
Privacy Policy Terms of Service Copyright Acknowledgements |
~~ 1 Cor. 10:31 ...whatever you do, do it all for the glory of God. ~~
Last updated: March 24, 2017